Transcribing audio uploaded to S3 AWS Transcribe AWS S3 Serverless Lambda Python
My sister had an interesting challenge for me recently. She had some audio that needed to be automatically run through AWS Transcribe from files uploaded to S3.
Initially I thought that AWS Step Functions would be great, but opted for a simpler solution using direct events. Normally a workflow tool would be more flexible for more complex solutions and hard coding event driven events tend to make solutions brittle when future changes come, but often simple is better.
Architecture Overview
Here’s a high level overview of the flow:
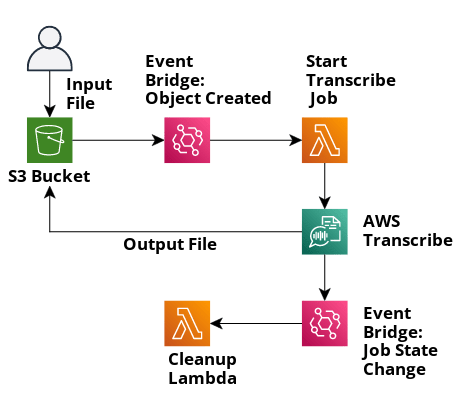
We can describe the flow thus:
- User uploads audio file (in mp3 format) to the
uploads/folder in the bucket - Event Bridge detects the created object and triggers the
Start Transcribe Joblambda function - The
Start Transcribe Joblambda initiates the AWS Transcribe Job and exits - AWS Transcribe completes the conversion from audio to text and writes the file back to the S3 bucket in the
output/folder - Event Bridge detects a state change in the AWS Transcribe job and triggers the
Cleanuplambda function
Guide
Let’s get into the how to build this system using the AWS console. Once you are familiar with the important steps, you may automate this process using an automated tool like Terraform
Create the bucket
- Load up the AWS console for S3: https://s3.console.aws.amazon.com/s3/buckets
- Click on the “Create Bucket” button
- Enter the bucket name and you can accept all default options. In this example I put in:
- Name:
transcribe-workflow-experiment
- Name:
- Once created, if you click on the bucket you should see a button for “Create Folder”. Use this button to create:
- A folder named
uploads - A folder named
output
- A folder named
Create your “Start Transcribe Job” Lambda
- Load up the lambda part of the AWS Console: https://us-east-1.console.aws.amazon.com/lambda/home
- Click on “Create Function”
- Use the following settings:
- Name: transcribe-workflow-start-transcribe
- RunTime: Python 3.9
- Architecture: x86_64
- And accept all other default parameters by clicking ‘Create Function’
Enhance the Lambda IAM role
When creating a new Lambda function, the default AWS settings will automatically create an IAM role associated with the function. This IAM roll will have the bare minimum permissions to execute the Lambda function and almost nothing else. We will need to add additional permissions to the IAM role in order to complete this overall architecture.
Once the Lambda function is created, click to see the details.
Click on ‘Configuration’
Then click on the ‘Role Name’ and it should open a new tab
You should now see the IAM permissions for the role associated with your Lambda function. We need to add the ability to:
- Access the S3 bucket we created previously
- Start AWS Transcribe jobs
First, we add S3 access. Click on the ‘Add Permissions’ dropdown and select ‘Create Inline Policy’. Click on the ‘JSON’ tab and input the following policy and click ‘Review Policy’. Make sure your bucket name you added replaces
transcribe-workflow-experimentin the JSON.
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "ListObjectsInBucket",
"Effect": "Allow",
"Action": ["s3:ListBucket"],
"Resource": ["arn:aws:s3:::transcribe-workflow-experiment"]
},
{
"Sid": "AllObjectActions",
"Effect": "Allow",
"Action": "s3:*Object",
"Resource": ["arn:aws:s3:::transcribe-workflow-experiment/*"]
}
]
}
- On the next screen, name like policy something descriptive like: “allow-bucket-access-for-transcribe-workflow”.
- Now we add permission to start AWS Transcribe jobs. Repeat the same steps with a new policy and this JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowTranscribeJobs",
"Effect": "Allow",
"Action": "transcribe:StartTranscriptionJob",
"Resource": "*"
}
]
}
Add the Lambda code
Next, we populate the python code that runs the Lambda function. You can see the code below is pretty straightforward, but there a couple things to note:
- The Lambda function does not actually interact directly with S3. So why did we add the IAM policy for S3 access? Because the AWS Transcribe job will use the same IAM role of the Lambda function that called it by default.
- The function instructs AWS Transcribe to output the results back to the same bucket, but to a different folder. See the parameters
OutputBucketNameandOutputKey. - The output file will be named after the
TranscriptionJobName. So we add a little utility function to ‘slugify’ the filename. To wit: “Audio File #3.mp3” becomes “audio-file-3-mp3”. - Additional Transcribe options can be added as you see fit. E.g. Leveraging a custom dictionary.
import json
import boto3
import logging
log = logging.getLogger()
log.setLevel(logging.INFO)
def lambda_handler(event, context):
transcribe = boto3.client("transcribe")
log.info("transcribe-workflow-start-job started...")
if event:
bucket = event["detail"]["bucket"]["name"]
key = event["detail"]["object"]["key"]
# The job name is important because the output file will be named after
# the original audio file name, but 'slugified'. This means it contains
# only lower case characters, numbers, and hyphens
job_name = slugify(key.split("/")[-1])
log.info(
f"transcribe-workflow-start-job: received the following file {bucket} {key}"
)
s3_uri = f"s3://{bucket}/{key}"
# Kick off the transcription job
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={"MediaFileUri": s3_uri},
LanguageCode="en-US",
OutputBucketName=bucket,
OutputKey="output/",
)
return {"statusCode": 200, "body": "Lambda: Start Transcribe Complete"}
# Small slugify code taken from:
# https://gist.github.com/gergelypolonkai/1866fd363f75f4da5f86103952e387f6
# Converts "Audio File #3.mp3" to "audio-file-3-mp3"
#
import re
from unicodedata import normalize
_punctuation_re = re.compile(r'[\t !"#$%&\'()*\-/<=>?@\[\\\]^_`{|},.]+')
def slugify(text, delim="-"):
"""
Generate an ASCII-only slug.
"""
result = []
for word in _punctuation_re.split(text.lower()):
word = normalize("NFKD", word).encode("ascii", "ignore").decode("utf-8")
if word:
result.append(word)
return delim.join(result)
Create the Cleanup Lambda function
Once the transcribe job is complete, we want this function to clean up a bit. Tasks needed:
- Move the original audio file to a
completedfolder orfailedfolder depending on the job outcome - (Optional) Delete the transcription job. Even though AWS Transcribe automatically deletes jobs after 90 days, it could reduce clutter in the AWS console
- (Optional) Contact a user with a notification that a job has completed
For this blog post, we will only manage the original audio file. We primarily wanted to highlight the capability of a post-processing Lambda function.
- Load up the Lambda part of the AWS Console: https://us-east-1.console.aws.amazon.com/lambda/home
- Click on “Create Function”
- Use the following settings:
- Name: transcribe-workflow-transcribe-completed
- RunTime: Python 3.9
- Architecture: x86_64
- And accept all other default parameters by clicking ‘Create Function’
Once complete, insert the following code:
import json
import boto3
import logging
log = logging.getLogger()
log.setLevel(logging.INFO)
def lambda_handler(event, context):
transcribe = boto3.client("transcribe")
s3 = boto3.client("s3")
log.info(f"transcribe-workflow-cleanup started...")
if event:
job_name = event["detail"]["TranscriptionJobName"]
log.info(f"Transcribe job: {job_name}")
response = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if not response:
return {"statusCode": 404, "body": "Job not found"}
# Now extract the name of the original file
# in the form:
# s3://transcribe-workflow-experiment/uploads/Sample Audio.mp3
original_audio_s3_uri = response["TranscriptionJob"]["Media"]["MediaFileUri"]
# Use [5:] to remove the 's3://' and partition returns the string split by the first '/'
bucket, _, key = original_audio_s3_uri[5:].partition("/")
_, _, media_file = key.partition("/")
log.info(f"Media file {media_file} is at: key {key} in bucket {bucket}")
# Job status will either be "COMPLETED" or "FAILED"
job_status = event["detail"]["TranscriptionJobStatus"]
new_folder = "completed/"
if job_status == "FAILED":
new_folder = "failed/"
# Tell AWS to 'move' the file in S3 which really means making a copy and deleting the original
s3.copy_object(
Bucket=bucket,
CopySource=f"{bucket}/{key}",
Key=f"{new_folder}{media_file}",
)
s3.delete_object(Bucket=bucket, Key=key)
return {"statusCode": 200, "body": "Lambda: Transcribe Cleanup Complete"}
Enhance the Lambda IAM role for 2nd Lambda function
We will need to add additional permissions to the IAM role in order to complete this overall architecture, specifically the ability to access the S3 bucket we created previously.
Once the Lambda function is created, click to see the details.
Click on ‘Configuration’
Then click on the ‘Role Name’ and it should open a new tab
You should now see the IAM permissions for the role associated with your Lambda function.
Click on the ‘Add Permissions’ dropdown and select ‘Create Inline Policy’. Click on the ‘JSON’ tab and input the following policy and click ‘Review Policy’. Make sure your bucket name you added replaces
transcribe-workflow-experimentin the JSON.{ "Version": "2012-10-17", "Statement": [ { "Sid": "ListObjectsInBucket", "Effect": "Allow", "Action": ["s3:ListBucket"], "Resource": ["arn:aws:s3:::transcribe-workflow-experiment"] }, { "Sid": "AllObjectActions", "Effect": "Allow", "Action": "s3:*Object", "Resource": ["arn:aws:s3:::transcribe-workflow-experiment/*"] } ] }On the next screen, name like policy something descriptive like: “allow-bucket-access-for-transcribe-workflow-cleanup”.
Now we add permission to query AWS Transcribe jobs. Repeat the same steps with a new policy and this JSON:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "QueryTranscriptionJobs",
"Effect": "Allow",
"Action": "transcribe:GetTranscriptionJob",
"Resource": "*"
}
]
}
Wire up events with EventBridge
Now we need to connect all these elements together. We do this with AWS EventBridge. EventBridge is kind of a universal event bus that can tap into many events throughout the AWS ecosystem. For example, the creation of an object in S3 can directly trigger a Lambda function. However, only EventBridge can detect the AWS Transcribe job status change. So to be consistent, we will use EventBridge for both S3 object creation and AWS Transcribe job status change.
EventBridge setup for new S3 object
In this setup, we will indicate to EventBridge to process all ‘Object Created’ events in the bucket ‘transcribe-workflow-experiment’ in the folder ‘uploads/’. More information about EventBridge patterns can be found in the AWS Docs. Any other objects created in other folders in the S3 bucket will not be processed by this rule.
Navigate to the EventBridge page in the AWS console: https://us-east-1.console.aws.amazon.com/events/home
From the left menu, select ‘Rules’
Click on the ‘Create Rule’ button
Use the following parameters and click ‘Next’
- Name: transcribe-workflow-new-object-rule
- Description: Notifies Lambda there is a new audio file in S3 in the ‘/uploads’ folder
- Event Bus: default
On the ‘Built Event Pattern’ page:
- Event source: AWS events or EventBridge partner events
- Scroll past the Sample Event section
- Creation method: Select ‘Custom Pattern (JSON Editor)’
- Insert the following and make sure you update the bucket name to your bucket
{ "source": ["aws.s3"], "detail-type": ["Object Created"], "detail": { "bucket": { "name": ["transcribe-workflow-experiment"] }, "object": { "key": [ { "prefix": "uploads" } ] } } }- Click ‘Next’
On the ‘Select target(s)` screen:
- Target 1: Select AWS Service
- In the dropdown, use target type ‘Lambda Function’
- Select the first Lambda function that starts the transcribe job
- Select ‘Next’
- You may skip tags and click ‘Next’ and then complete the process
EventBridge setup for AWS Transcribe Job Complete
From the left menu, select ‘Rules’
Click on the ‘Create Rule’ button
Use the following parameters and click ‘Next’
- Name: transcribe-workflow-job-complete-rule
- Description: Notifies Lambda the transcribe job is complete
- Event Bus: default
On the ‘Built Event Pattern’ page:
- Event source: AWS events or EventBridge partner events
- Scroll past the Sample Event section
- Creation method: Select ‘Custom Pattern (JSON Editor)’
- Insert the following:
{ "source": ["aws.transcribe"], "detail-type": ["Transcribe Job State Change"], "detail": { "TranscriptionJobStatus": ["COMPLETED", "FAILED"] } }- Click ‘Next’
On the ‘Select target(s)` screen:
- Target 1: Select AWS Service
- In the dropdown, use target type ‘Lambda Function’
- Select the second Lambda function that cleans up the transcribe job
- Select ‘Next’
- You may skip tags and click ‘Next’ and then complete the process
Test it out
You can try this out by using the AWS Console and uploading files into the ‘uploads/’ folder of the bucket. Try loading an audio file and seeing the output. Next, try loading a non-audio file like a jpg and watch the file get swept into the ‘failed’ folder.
Next steps
As you can see, this is essentially a two step workflow. More tasks can be added to the 2nd Lambda function if you wish. To further extend this, you can insert Step Functions to have a more flexible workflow. Most of the code will be the same with some slight tweaks to the event formats.
One difficulty you will have with Step Functions is to pause the flow while AWS Transcribe is processing the job. Step Functions generates a token that is needed to resume the workflow and that token will not be stored by AWS Transcribe. So you’d need a mechanism to either store the token in something like DynamoDB or do some deep inspection of the workflow to extract the resume token.
Regardless, I hope this helps someone working on a similar effort.